【フォルマント分析】言語パスバンド分析による語学学習効率化

この記事の目次
この記事で学べるスキル
例えば、語学学習の中で、日本語と英語は相性が悪いとされていますが、自分の英語の音声を録音し、フォルマント分析などを用いて発音が正しいかどうか?
ネイティブに近づいているかどうか?
可視化してデータとして学習に使用していくことができます。
アプリ開発はもちろん、語学学習にも積極的にPythonを活用してみてはいかがでしょうか?
筆者のプログラミング専門のブログにてPythonの語学学習のためのアイディアも公開しているので是非参考にしてみてください。

簡易紹介:こうたろう
1986年生まれ
音大卒業後日本、スウェーデン、ドイツにて音楽活動
その後金田式DC録音のスタジオに弟子入り
プログラミング(C)を株式会社ジオセンスのCEO小林一英氏よりを学ぶ
現在はヒーリングサウンド専門のピアニスト、またスタジオでは音響エンジニア、フォトグラファーなどマルチメディアクリエーターとして活動中
当記事ではプログラマー、音響エンジニアとして知識とスキルをシェアしていきます
さて、本日の話題に入りましょう。
各言語の中には発音にも音響特性があり、例えば英語と日本語は相性が抜群に悪いです。
そのため、聞き取りが難しかったりします。
例えばスペイン語の場合はカタカナで聞こえてきますし、日本人がそのままカタカナ読みをすると「あなたはどこでネイティブのスペイン語を学んだの?」って驚かれたりするわけです。
それは言語パスバンドの類似性が関係しています。
本日はそんな言語パスバンドと語学学習について学んでいきましょう。
ちなみに言語パスバンドが近く、日本人が論理的に効率よく学べる言語を5つピックアップしました。
- 韓国語:言語パスバンドが似ており、文法構造も似ています。
- 中国語(特に北京語):言語パスバンドの類似性と漢字の使用が学習を助けます。
- インドネシア語:文法構造が単純で、発音が比較的簡単です。
- マレー語:文法が単純で、発音も比較的簡単です。
- スペイン語:ロマンス語族に属し、発音が日本語話者にとって比較的簡単です。また、文法構造は日本語とは異なりますが、規則性が高く、学習しやすい面があります。
ポイントここからスペイン語が日本人にとって相性がいい根拠を提示しましょう!
当スタジオではスペイン語学習コンテンツを用意していますので、是非日本人と相性の良いスペイン語学習をはじめてみてください。
当スタジオではスペイン語学習コンテンツを用意していますので、是非日本人と相性の良いスペイン語学習をはじめてみてください。
言語パスバンドの類似性を分析
ここからはより論理的に解析していきます。
Kotaro Studioは音響の専門チャンネルですので、Pythonを使ってしっかりと音響を分析して考えていきましょう。
言語パスバンドを実際の音声データから抽出することはPythonを使えば簡単です。
音声信号処理の技術を用いて、音声データから周波数成分を分析するわけです。
スペイン語に精通しているKotaro Studioですから、スペイン語の音声と日本語の音声の二種類で解析してみます。
スペイン語の音声はこちらの動画、フォルクローレのリズム解説の動画制作のときに収録したDPA4006の音声。
解説はピアナ・ナッチョです。
ナッチョはアルゼンチンで活躍するパーカッション奏者で、アルゼンチンタンゴのマエストロSebastián Pianaのお孫さん。
全体のプロセスとサンプルコード
それでは全体のプロセスを把握しながら実際に進めていきましょう。
必要なライブラリをインストール
まずはこの解析に必要なライブラリをpipでインストールしてください。
pip install librosa numpy matplotlib
librosaライブラリを使用して、日本語とスペイン語の音声ファイルを読み込みます。
この際、サンプリングレートを統一することが重要になるわけですが、違っていても構いません。
librosaライブラリを使用すると、音声ファイルを読み込む際にサンプリングレートを指定できます。
例えば今回筆者が準備しているファイルは96kHzのスペイン語語音声ファイルと48kHzの日本語音声ファイルがありますが、どちらも48kHzに統一することができます。
以下のコードはその方法を示しています。
import librosa
# スペイン語語の音声ファイルを48kHzで読み込む(96kHzから48kHzにダウンサンプリング)
spanish_audio, sr = librosa.load('path_to_japanese_audio_file.wav', sr=48000)
# 日本語語の音声ファイルを48kHzで読み込む(既に48kHzなので変更なし)
japanese_audio, _ = librosa.load('path_to_spanish_audio_file.wav', sr=48000)
元々同じであればこのコードで読み込めます。
import librosa
# 日本語の音声ファイルを読み込む
japanese_audio, sr = librosa.load('path_to_japanese_audio_file.wav', sr=None)
# スペイン語の音声ファイルを読み込む
spanish_audio, _ = librosa.load('path_to_spanish_audio_file.wav', sr=sr)
フーリエ変換
フーリエ変換して解析していきます。
import numpy as np # FFTを使用して周波数成分を取得 japanese_fft = np.abs(np.fft.fft(japanese_audio)) spanish_fft = np.abs(np.fft.fft(spanish_audio)) # 周波数ビンを計算 freqs = np.fft.fftfreq(len(japanese_fft), 1/sr)
データの可視化
ここまできたらデータを可視化していきます。
import matplotlib.pyplot as plt
# 日本語とスペイン語のFFTスペクトルをプロット
plt.figure(figsize=(12, 6))
plt.plot(freqs, japanese_fft, label='Japanese')
plt.plot(freqs, spanish_fft, label='Spanish')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Amplitude')
plt.title('Frequency Spectrum of Japanese and Spanish')
plt.legend()
plt.show()
デバッグ
さて、ここからデバッグの作業です。
全体の流れを理解したとして、当然様々な問題が起こると思います。
ここで想定されるバグやエラーの解決策を先に潰しておきましょう。
numpyのバージョン
numbaとnumpyのバージョンの互換性に関連しているようです。
「Numba needs NumPy 1.20 or less」というエラーが出る場合、インストールされているnumpyのバージョンがnumbaに対応していないことを示しています。
この問題を解決するためには、numpyのバージョンを1.20以下にダウングレードする必要があります。
コマンドで簡単にできますので、調整してください。
pip uninstall numpy
pip install numpy==1.20
FFTのトリミング
エラーメッセージ「x and y must have same first dimension」が出る場合は、プロットしようとしているx(周波数)とy(振幅)のデータが同じ長さでないことを示しています。
これは、日本語とスペイン語の音声ファイルの長さが異なるために発生しています。
この問題を解決するためには、FFTの結果を同じ長さにトリミングする必要があります。
ポイント
音声ファイルを1分(60秒)にトリミングするためには、まず音声ファイルのサンプリングレートに基づいて、1分間のサンプル数を計算します。
その後、各音声ファイルをこのサンプル数に合わせてトリミングします。
以下のコードは、このプロセスを実装したものです。
コメントアウトの解説とともに進めてみてください。
import librosa
import numpy as np
import matplotlib.pyplot as plt
# 音声ファイルの読み込み
japanese_audio, sr = librosa.load('path_to_japanese_audio_file.wav', sr=48000)
spanish_audio, _ = librosa.load('path_to_spanish_audio_file.wav', sr=48000)
# 1分間のサンプル数を計算(サンプリングレート * 秒数)
one_minute_samples = 60 * sr
# 両方の音声ファイルを1分にトリミング
japanese_audio = japanese_audio[:one_minute_samples]
spanish_audio = spanish_audio[:one_minute_samples]
# FFTを使用して周波数成分を取得
japanese_fft = np.abs(np.fft.fft(japanese_audio))
spanish_fft = np.abs(np.fft.fft(spanish_audio))
# 周波数ビンを計算
freqs = np.fft.fftfreq(len(japanese_fft), 1/sr)
# 日本語とスペイン語のFFTスペクトルをプロット
plt.figure(figsize=(12, 6))
plt.plot(freqs[:len(freqs)//2], japanese_fft[:len(freqs)//2], label='Japanese')
plt.plot(freqs[:len(freqs)//2], spanish_fft[:len(freqs)//2], label='Spanish')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Amplitude')
plt.title('Frequency Spectrum of Japanese and Spanish (1 minute)')
plt.legend()
plt.show()
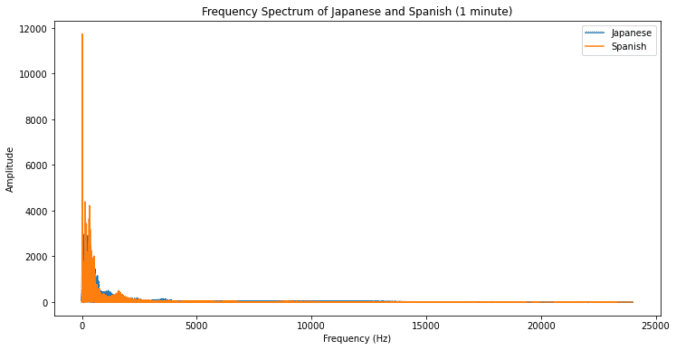
無事にこのようにプロットすることができました。
少しみにくいので別々にプロットしてみましょう。
import librosa
import numpy as np
import matplotlib.pyplot as plt
# 音声ファイルの読み込み
japanese_audio, sr = librosa.load('path_to_japanese_audio_file.wav', sr=48000)
spanish_audio, _ = librosa.load('path_to_spanish_audio_file.wav', sr=48000)
# 1分間のサンプル数を計算(サンプリングレート * 秒数)
one_minute_samples = 60 * sr
# 両方の音声ファイルを1分にトリミング
japanese_audio = japanese_audio[:one_minute_samples]
spanish_audio = spanish_audio[:one_minute_samples]
# FFTを使用して周波数成分を取得
japanese_fft = np.abs(np.fft.fft(japanese_audio))
spanish_fft = np.abs(np.fft.fft(spanish_audio))
# 周波数ビンを計算
freqs = np.fft.fftfreq(len(japanese_fft), 1/sr)
# 日本語のFFTスペクトルをプロット
plt.figure(figsize=(12, 6))
plt.plot(freqs[:len(freqs)//2], japanese_fft[:len(freqs)//2], label='Japanese')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Amplitude')
plt.title('Frequency Spectrum of Japanese (1 minute)')
plt.legend()
plt.show()
# スペイン語のFFTスペクトルをプロット
plt.figure(figsize=(12, 6))
plt.plot(freqs[:len(freqs)//2], spanish_fft[:len(freqs)//2], label='Spanish')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Amplitude')
plt.title('Frequency Spectrum of Spanish (1 minute)')
plt.legend()
plt.show()

フォルマント分析
フォルマント分析において、音声ファイルの長さを統一する必要は必ずしもありませんが、サンプリング周波数の統一は重要になります。
フォルマント分析は音声の周波数特性を調べるもので、特に母音の特徴的な周波数帯域(フォルマント)を識別します。
この分析では、音声の特定の瞬間や特定の母音に焦点を当てることが多いため、全体の長さが異なっていても問題ありません。
そのためこのコードではスペイン語を48khzにする設定しか入っていません。
import librosa
import numpy as np
import matplotlib.pyplot as plt
# 日本語の音声ファイルを読み込む(48kHz)
japanese_audio, sr = librosa.load('path_to_japanese_audio_file.wav', sr=48000)
# スペイン語の音声ファイルを読み込む(96kHzから48kHzにダウンサンプリング)
spanish_audio, _ = librosa.load('path_to_spanish_audio_file.wav', sr=48000)
# フォルマントを分析する関数
def analyze_formants(audio, sr, n_formants=5):
# 短時間フーリエ変換(STFT)を実行
stft = np.abs(librosa.stft(audio))
# メルスペクトログラムを計算
mel_spect = librosa.feature.melspectrogram(S=stft, sr=sr)
# メルスペクトログラムをデシベル単位に変換
mel_spect_dB = librosa.power_to_db(mel_spect, ref=np.max)
# 中央のフレームを選択
central_frame = mel_spect_dB[:, mel_spect_dB.shape[1] // 2]
# フォルマントのピークを検出
peaks = librosa.util.peak_pick(central_frame, pre_max=1, post_max=1, pre_avg=1, post_avg=1, delta=0, wait=0)
# 最も強いn_formants個のピークを選択
formants = sorted(peaks, key=lambda x: central_frame[x], reverse=True)[:n_formants]
return formants
# 日本語のフォルマントを分析
japanese_formants = analyze_formants(japanese_audio, sr)
# スペイン語のフォルマントを分析
spanish_formants = analyze_formants(spanish_audio, sr)
# フォルマントをプロット
plt.figure(figsize=(12, 6))
librosa.display.specshow(librosa.amplitude_to_db(np.abs(librosa.stft(japanese_audio)), ref=np.max), sr=sr, x_axis='time', y_axis='log')
plt.title('Formants in Japanese Audio')
plt.colorbar(format='%+2.0f dB')
plt.show()
plt.figure(figsize=(12, 6))
librosa.display.specshow(librosa.amplitude_to_db(np.abs(librosa.stft(spanish_audio)), ref=np.max), sr=sr, x_axis='time', y_axis='log')
plt.title('Formants in Spanish Audio')
plt.colorbar(format='%+2.0f dB')
plt.show()
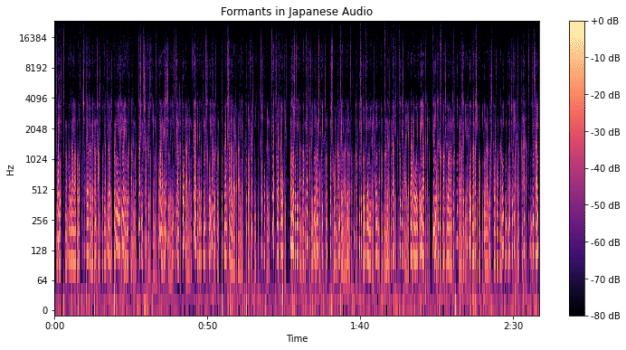
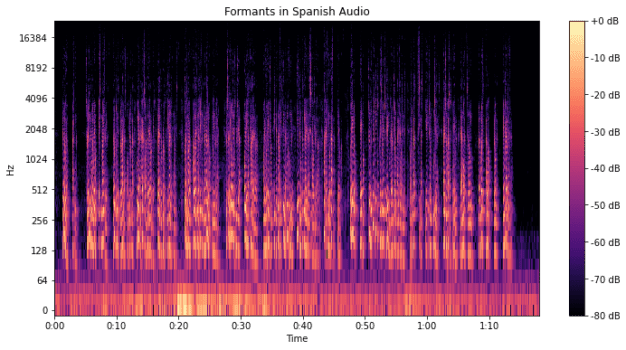
ポイント
フォルマントは、音声スペクトル内の特定の周波数帯域で、エネルギーが集中している領域です。
これらは、話者の口腔内での音の共鳴によって生じます。
母音は、口腔の形状によって異なるフォルマントパターンを生成します。
例えば、「a」、「i」、「u」などの母音は、それぞれ異なるフォルマント周波数を持ち、これらが解析結果として反映される仕組みになっています。
通常、最初の二つまたは三つのフォルマント(F1、F2、F3)が母音の特徴を識別するのに十分というわけです。
F1は母音の開放度、F2は前舌か後舌かを示します。
出力されたスペクトログラム上で、明確な明るい帯(高エネルギー領域)を探してください。
これらはフォルマントを示しています。
異なる母音は異なるフォルマントパターンを持ちます。例えば、F1とF2の位置関係は母音の種類を示唆します。
異なる言語のフォルマントを比較することで、言語間の母音の違いを理解することができます。
例えば、同じ母音でも言語によってフォルマントの位置が異なる場合があります。
フォルマント分析は特に母音に焦点を当てた分析となっているため、音声サンプルに母音が含まれていることが重要になります。
言語パスバンドについての解説
言語パスバンドは、特定の言語が使用する音声の周波数範囲を指します。
この概念は音声学、音響学、および言語学の分野で重要な要素になります。
ポイント
音声認識システムは、特定の言語のパスバンドを考慮して設計されることが多く、これにより認識精度が向上します。
この分析は音声認識システムなどには欠かせない分野となります。
パスバンドの決定要因
母音と子音母音は通常、低い周波数で発音され、子音は高い周波数で発音されます。
言語によって使用される母音と子音の種類が異なるため、パスバンドも異なります。
言語によって使用される母音と子音の種類が異なるため、パスバンドも異なります。
音響特性言語の音響特性、特にフォルマント(共鳴周波数)は、パスバンドを決定する重要な要素です。
フォルマントは、母音の特徴を決定し、言語ごとに異なります。
フォルマントは、母音の特徴を決定し、言語ごとに異なります。
話者の特性話者の年齢、性別、身体的特徴なども、発声する周波数範囲に影響を与えます。
パスバンドの測定と分析
スペクトル分析音声のスペクトル分析により、特定の言語の音声がどの周波数範囲に集中しているかを観察できます。
フォルマント分析フォルマントの位置を分析することで、言語の特徴的な母音の周波数範囲を特定できます。
比較研究異なる言語間のパスバンドを比較することで、言語間の音声的類似性や差異を明らかにすることができます。
応用分野
- 言語教育:言語パスバンドの理解は、外国語の発音教育に役立ちます。
- 音声認識:音声認識システムは、特定の言語のパスバンドに基づいて最適化されます。
- 音声合成:音声合成技術では、自然な音声を生成するために言語パスバンドが考慮されます。
言語パスバンドの理解は、言語の音声的特性を深く理解するための鍵となり、多くの応用分野でその知識が活用されています。
まとめ
本日はスペイン語と日本語の解析でした。
というのも他の言語でのスタジオで録音した(著作権の問題を持っていないファイル)がないので、解析できませんでしたが、他の音声サンプルを持っている方は同様の方法で解析してみてください。
例えば、語学学習の中で、日本語と英語は相性が悪いとされていますが、自分の英語の音声を録音し、フォルマント分析などを用いて発音が正しいかどうか?
ネイティブに近づいているかどうか?
可視化してデータとして学習に使用していくことができます。
アプリ開発はもちろん、語学学習にも積極的にPythonを活用してみてはいかがでしょうか?








